前情提要
我的一位朋友因为没有正版 IDM 也懒得折腾, 经常会把他在某直播课的录播视频链接发给我, 让我用 IDM 代为下载保存, 因为这些视频过几天就会隐藏或者变为付费. 帮了一段时间的忙以后, 我决定看看这玩意到底咋回事儿, 能不能写个爬虫脚本让他自己下载.
经过几分钟的研究, 发现其实非常简单, 就写了个小脚本顺利完成任务. 并有了这篇文章以作记录和帮助初学 Python 爬虫的朋友更进一步.
下文中我们将此视频网站称之为 Y 站 方便描述.
文内配图为了隐私处理, 可能有较多马赛克, 一般都是涉及具体的 userId 或者 videoId 等参数, 不影响阅读, 请见谅. 接下来进入正题.
分析请求
爬虫分类
爬虫分为很多种, HTML 爬虫, API 爬虫, App 爬虫等等… 我们这里讲的则是 API 爬虫. 就是通过抓包, 分析, 逆向等手段, 获取需要爬取的数据的 API 接口, 实现调用 API 完成数据获取.
收集线索
Y 站的视频链接都是这种格式: https://air.XXXXX.top/live/XXXXXXX?_uds=hyyy_qgg_live, 这个 XXXXX 我们称之为 videoId. 一般来说, 在线播放的视频都是通过 m3u8 格式的切片视频整合而成, 那这个 m3u8 的文件也通常会通过某个 API 接口获取, 再由前端解析并加载视频.
那第一步直接在浏览器打开, 用开发者工具 (俗称 F12) 的 网络 (Network) 查看请求. 我们直接选择只查看 Fetch/XHR 请求, 也就是 API 请求.
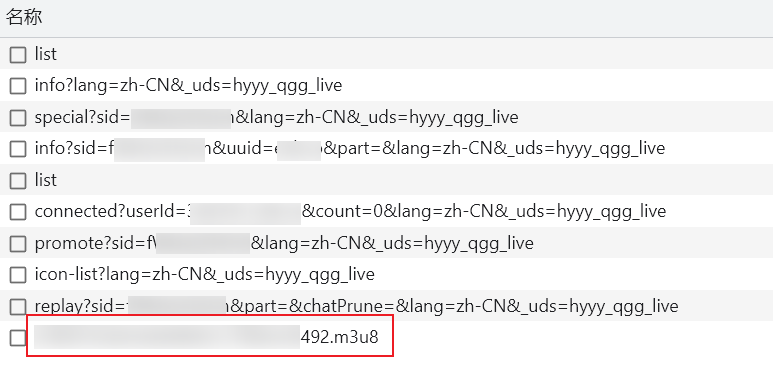
可以看到, 这里有不少的请求, 最后一条尤为显眼. m3u8 文件, 正是我们需要的. 既然有了这个, 那肯定有相关的 API 来获取这个文件.
依次分析上面的请求, 简单来说就是看响应内容, 定位到了这个请求:

可以看到, 这个 URL 为 https://air.XXXXX.top/api/air/room/replay 的接口响应数据中存在一个 m3u8 文件的地址, 并且和上面浏览器加载的一样. 可以判断这就是获取视频流的接口.
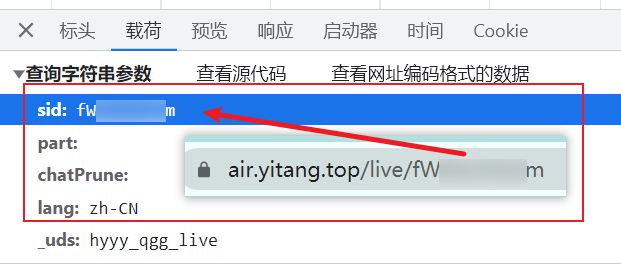
接下来分析请求参数, 发现视频链接中的 videoId 在这个请求中以名为 sid 的参数传递给了后端, 盲猜 sid 是 streamId 的简称. 其他参数看起来不是很重要, 暂时忽略.
分析鉴权
知道了哪个接口是用来获取我们需要的数据的, 现在应该开始分析接口如何鉴权的. 我一般通过检查 Cookie 和 LocalStorage 两个常见储存位置, 再和请求参数, 请求头的值一起加以分析, 判断鉴权的方式.
先检查 Cookie 感觉都是一些无关紧要的东西, 比较有用的也只是个类似 uid 的东西.
再看 LocalStorage, 发现了一个似乎很重要的东西叫 token, 然后又在请求头中的 Authorization 字段找到了一样的数据, 基本可以认定这就是鉴权所用的令牌. 还是很简单的.
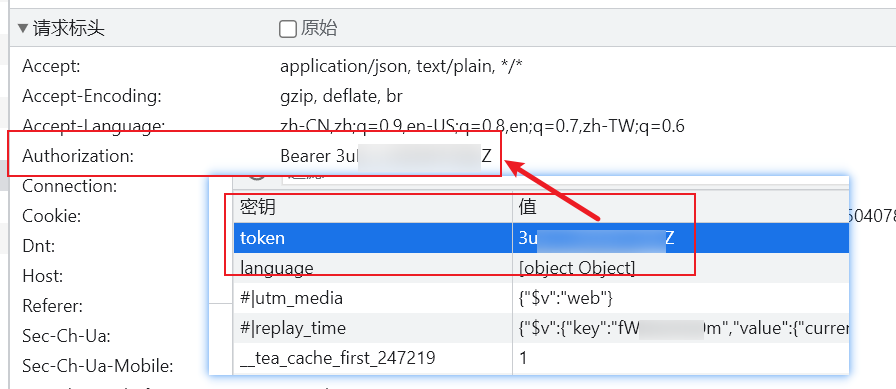
再检查了一下请求中其余的请求头和参数, 感觉大部分没有业务功能, 可能是一些用于做访问分析的参数, 暂时可以不管, 之后有问题再来看.
测试接口
经过分析, 我们知道在 GET https://air.XXXXX.top/api/air/room/replay 这个接口携带 sid 参数和鉴权令牌, 应该可以获取到视频流的地址. 开始上代码测试.
| |
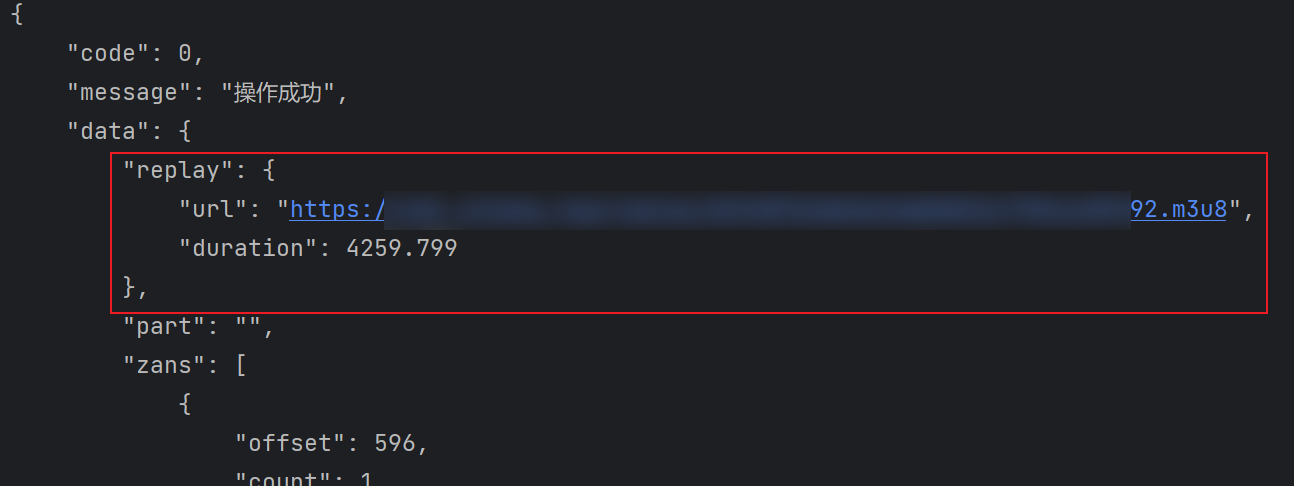
很顺利, 直接拿到了想要的结果. 看起来 Y 站对鉴权的反爬基本是没做额外处理.
下载视频
我们刚才获得的 m3u8 文件中包含了视频所有的切片, 我们需要下载每一个切片, 最后合并, 就是最终需要的视频了.
Python 有一个就叫做 m3u8 的模块可以用于处理该文件, GitHub 地址在此. 可以直接使用 pip 安装. 根据文档, 调用函数即可查看每一个切片的地址.
| |
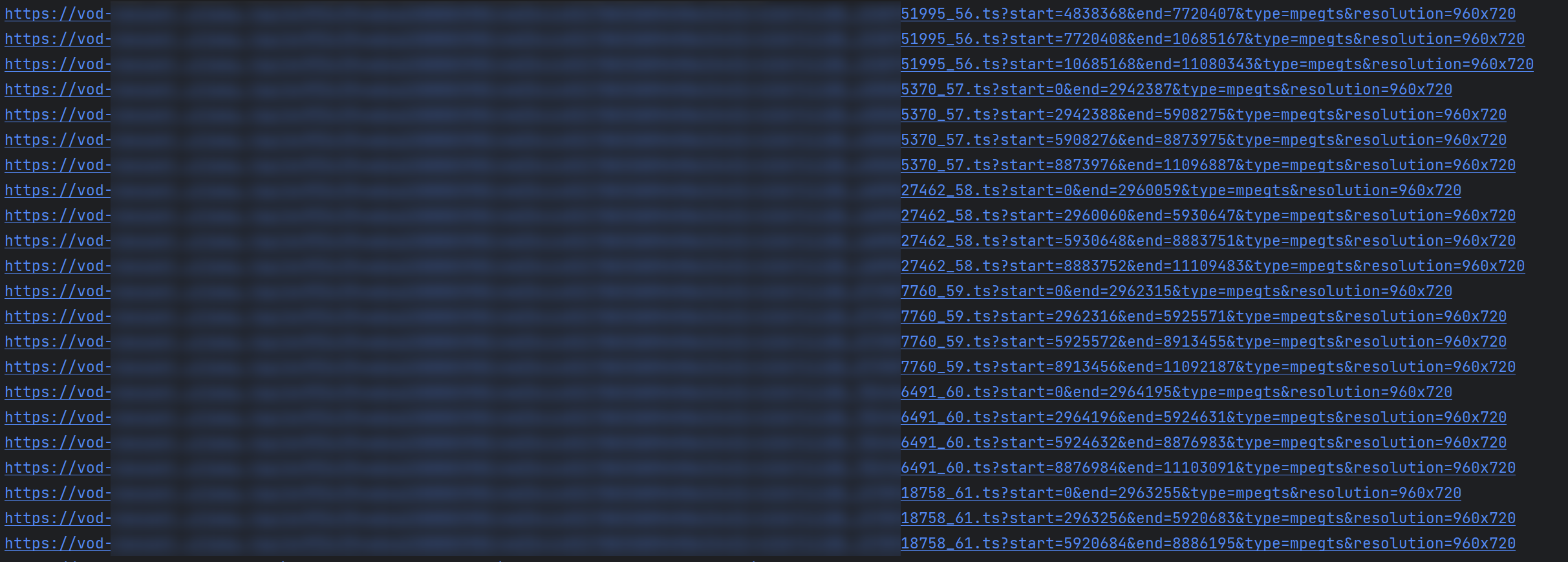
可以看到输出了非常多个视频切片地址, 我们需要依次下载. 方便查看运行情况, 加上一个 tqdm 模块展示进度.
| |

现在已经可以运行了, 但下载速度很慢.
多线程下载
Python 自带一个 threading 可以用于处理多线程事务. 我们简单利用即可.
已知我们需要现在数个切片文件, 对于 Y 站来说, 这个数量通常在几百到上千, 我决定设置并发数为 12, 也就是同时下载 12 个. 这个数值可以根据实际情况, 比如带宽用量, 服务器是否有限制等, 进行合理规划, 不一定是越大越好. 任何情况建议不要超过 16.
写两个函数, 一个用于下载单个文件, 一个用于处理多线程事务.
| |
此处 thread = threading.Thread(target=download_file, args=(url, filename)) 用于创建子线程, thread.start() 启动该线程. 最后的 thread.join() 是用于等待所有线程结束.
稍微优化一下代码, 根据视频流的地址, 生成一个 task_id. 再给每一个 URL 一个文件名, 用于后续合并.
| |
现在每个切片都以 (url, filename) 的形式保存在 urls 这个数组中.
将所有视频 URL 按照并发数分组, 依次下载.
| |
写一个合并所有文件的函数
| |
现在代码是这个样子的 (函数未展示)
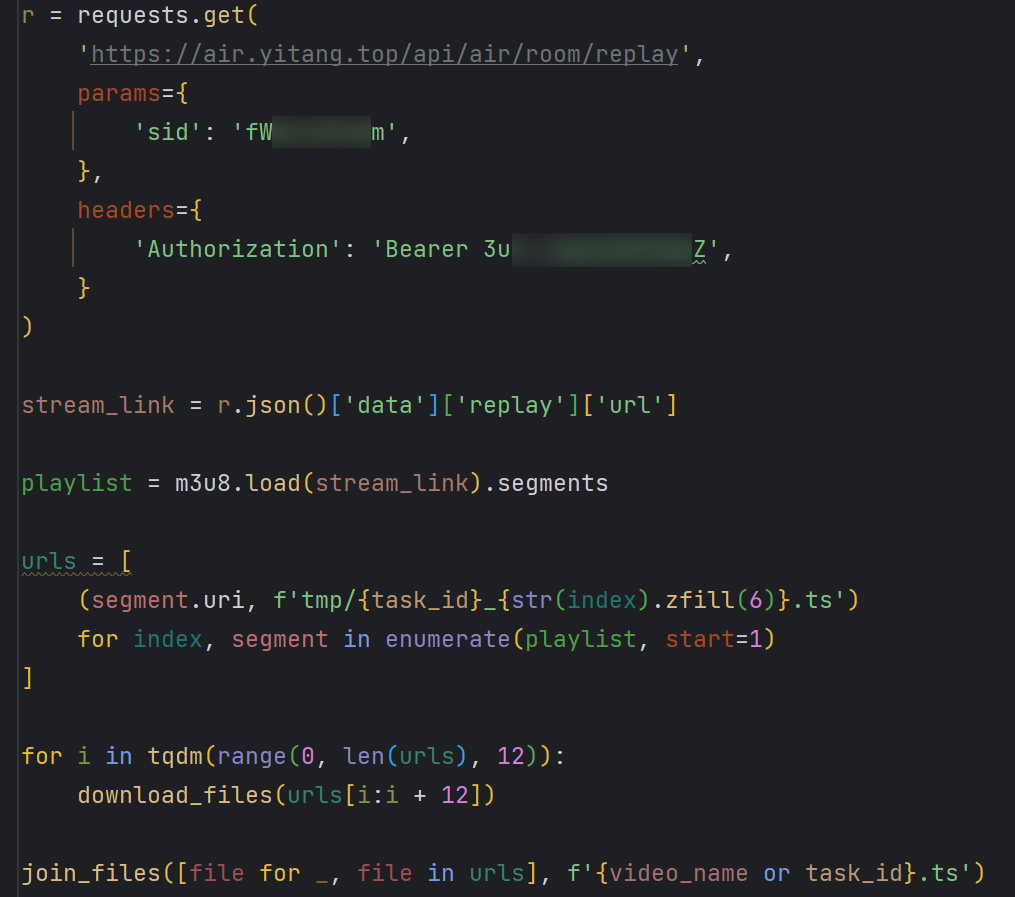
现在运行试试

总用时只需要 20 秒, 之前需要两分钟.
优化与包装
到现在为止, 这个 demo 的基础功能已经写完了. 但如果想要让别人用, 那需要将其优化一下, 加入更多提示词和进度信息.
提示让用户输入
token1 2 3 4 5 6 7 8 9 10def input_token() -> str: global token token = input( '在 Y 站面按 F12 打开控制台,输入 localStorage.token 即可查看 token\n' '请输入 token: ' ) with open(token_file, 'w') as f: f.write(token) return token自动从视频链接中解析
sid1 2 3def get_stream_id(url: str) -> str: # https://air.XXXXX.top/live/XXXXXX?_uds=hyyy_qgg_live return url.split('/')[-1].split('?')[0]获取视频标题 (从另一个抓到的接口中)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15def get_video_name(sid: str) -> Optional[str]: r = requests.get( url='https://air.XXXXX.top/api/air/room/info', params={ 'sid': sid, }, headers={ 'Authorization': 'Bearer ' + token, } ).json() try: return r['data']['title'] except KeyError: return None
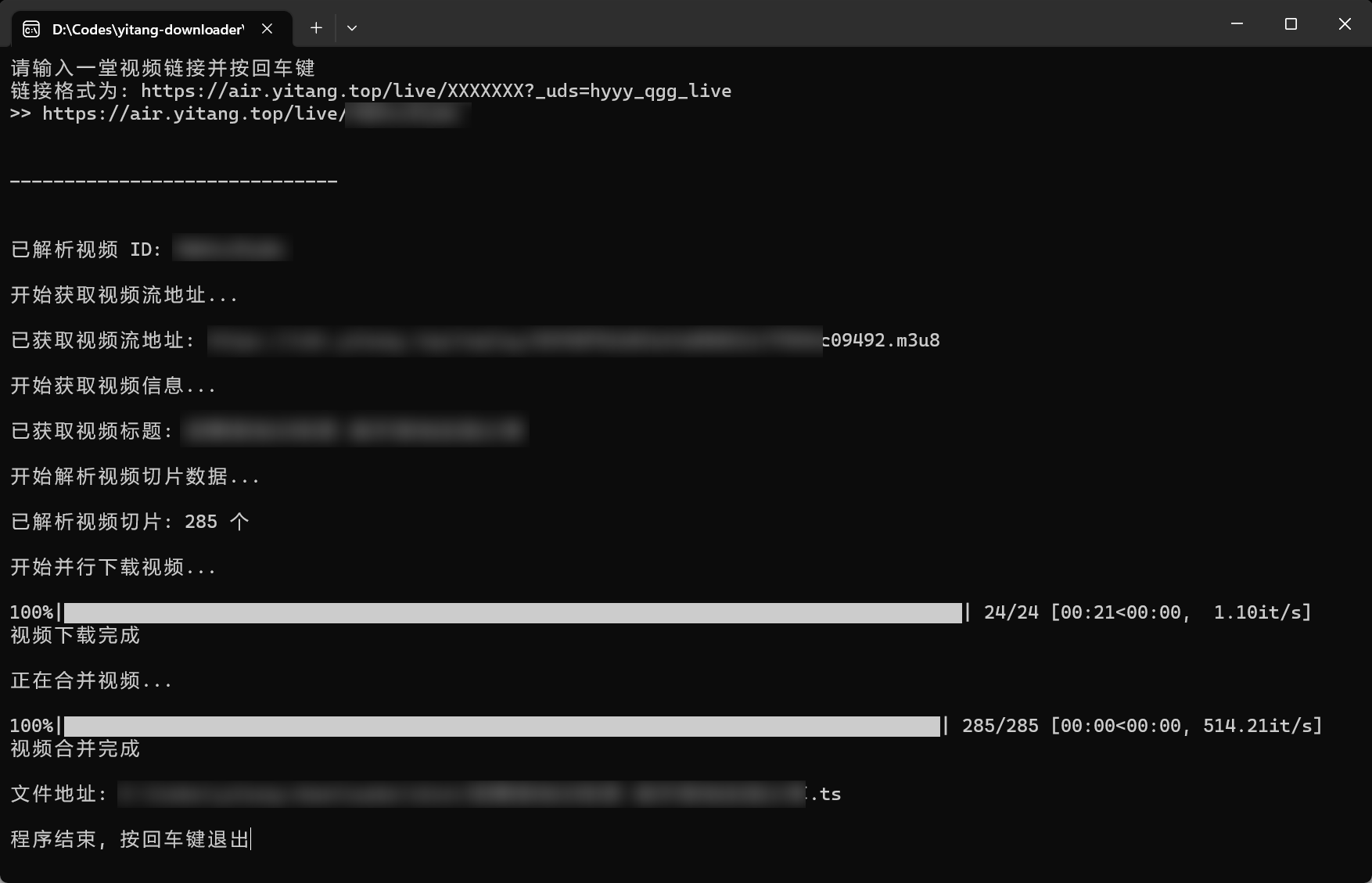
最终效果
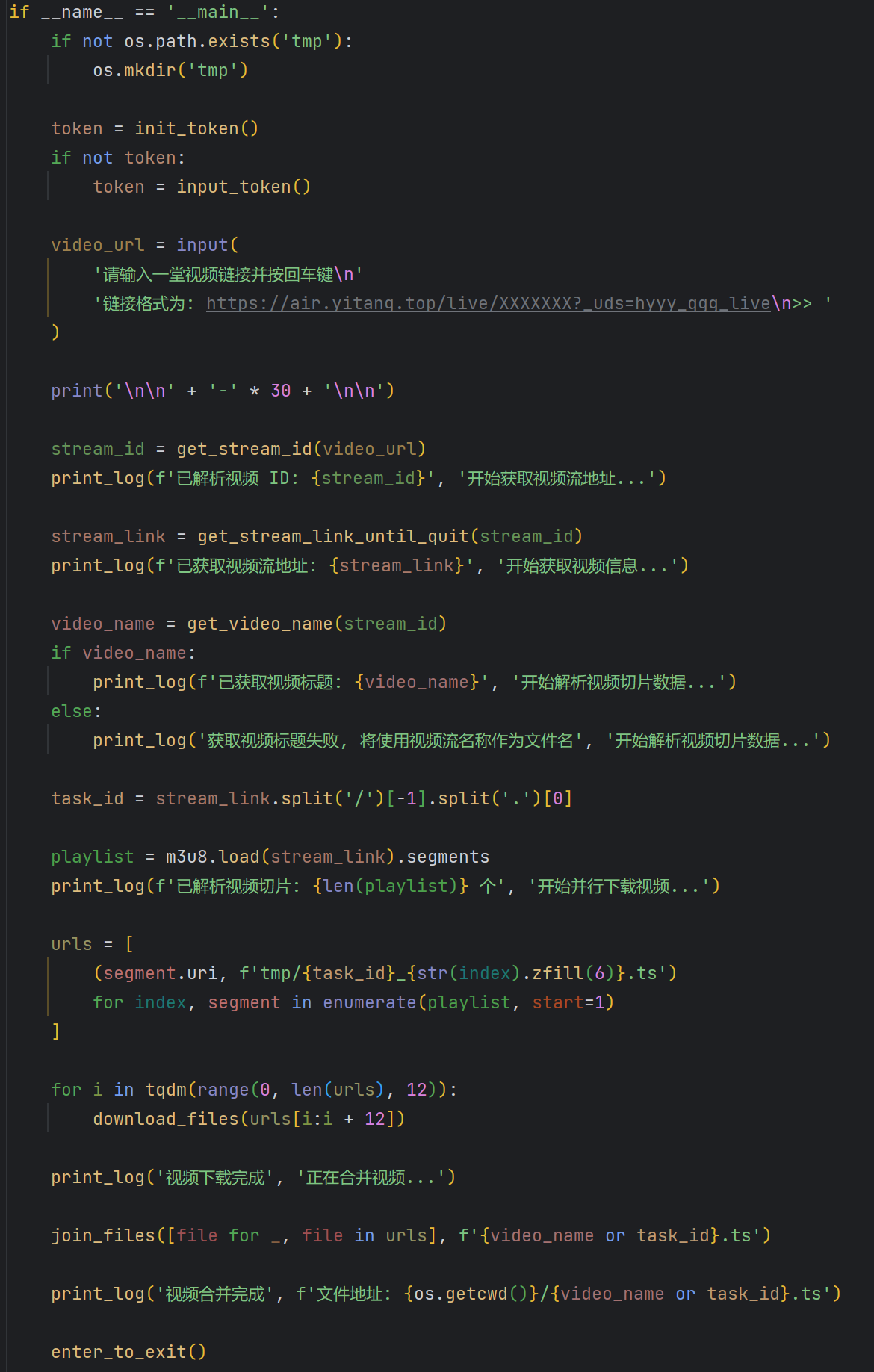
最后
由于项目过于简单, 而且几乎所有代码已经展示在文中, 故不提供完整代码下载方式. 自己动手, 多多益善.
在进行此项目时, 还发现了 Y 站获取视频流文件的这个接口, 对用户权限校验似乎不太对, 有一些其他接口提示无权限查看的视频, 可以直接通过这个接口请求视频流文件. 而这个视频流文件存放于 CDN, 且未设置鉴权. 不过因为文件名极长, 不太可能存在穷举爆破情况. 但视频流中的视频切片实际托管于腾讯云点播服务, 也没有鉴权, 其中可能有不少潜在问题可以优化.